Skip to content 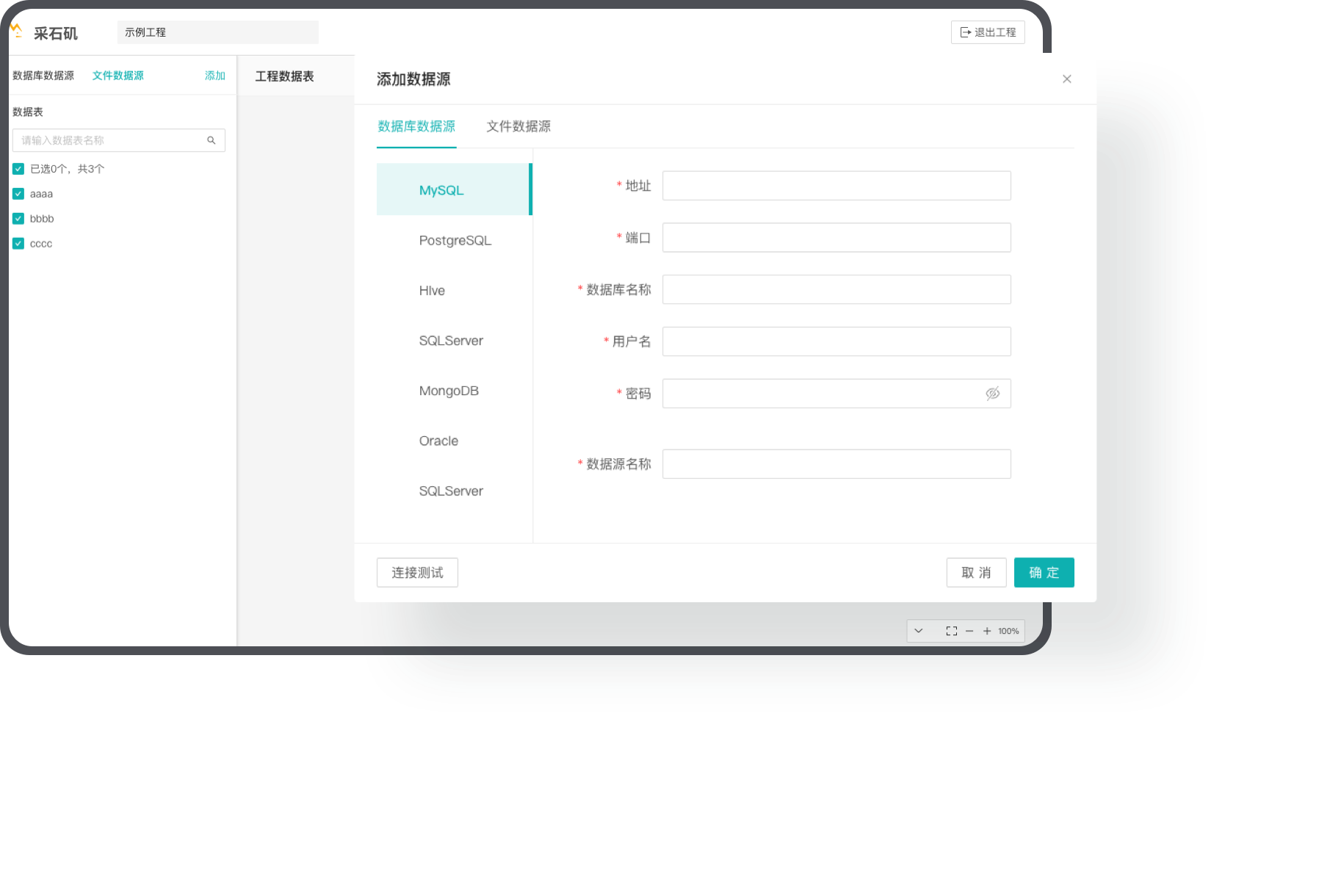

 关河智图
关河智图采石矶
规则和ML结合的智能数据质量评估与提升系统
愿景
轻松高效完成数据准备,让企业随时获得所需数据
理论
数据质量实体增强规则(REE) 融合AI和逻辑规则,构建基于可信数据质量自我增强系统
技术
提供了自动化智能方法,可全面、深度诊断、修复数据问题
全球大数据 质量系统面临的挑战
挑战一:
能否将逻辑规则可解释性和AI的强表达力相结合?
挑战二:
能否扩展大型数据集,且具备正确性保证的数据修正?
挑战三:
实体解析(ER)、冲突解决(CR)、缺失值插补(MI)、时序推断(TD)这四个关键问题在数据质量系统中会相互影响。一个高质量的数据系统是否可以同时处理这四个问题?
采石矶基于 原创理论应对数据质量挑战
逻辑规则和机器学习相结合
全自动并行规则发现
具备正确性保证的数据自动修正
并行查错和增量并行查错
增量计算,实时对应数据变化
如何让每一位
易上手
拖拉拽式操作,无需编写代码即可让目标用户快速、轻松地处理数据
易操作
提供可视化、分层级界面,可清晰展示数据关系,精确表达业务逻辑
可解释
基于机器学习和深度学习技术,形成可用自然语言解释的数据规则,帮助用户理解
一站式
提供数据接入、处理、规则发现、查错纠错能力,实现数据全流程管理
与采石矶一起开启全新的数据处理旅程
数据处理
规则发现
接入准备
数据剖析
查错纠错
可视化
提供可视化界面,可以快速轻松地分析数据
自动化
无需编写代码,即可自动执行数据清理和规范化任务
智能化
智能探查和纠错,并通过严谨的评分机制,让数据处理有理有据
数据接入
对需要进行质量分析处理的数据源,执行统一接入,集中管理,并支持通过数据标签对数据源进行分类查询访问。
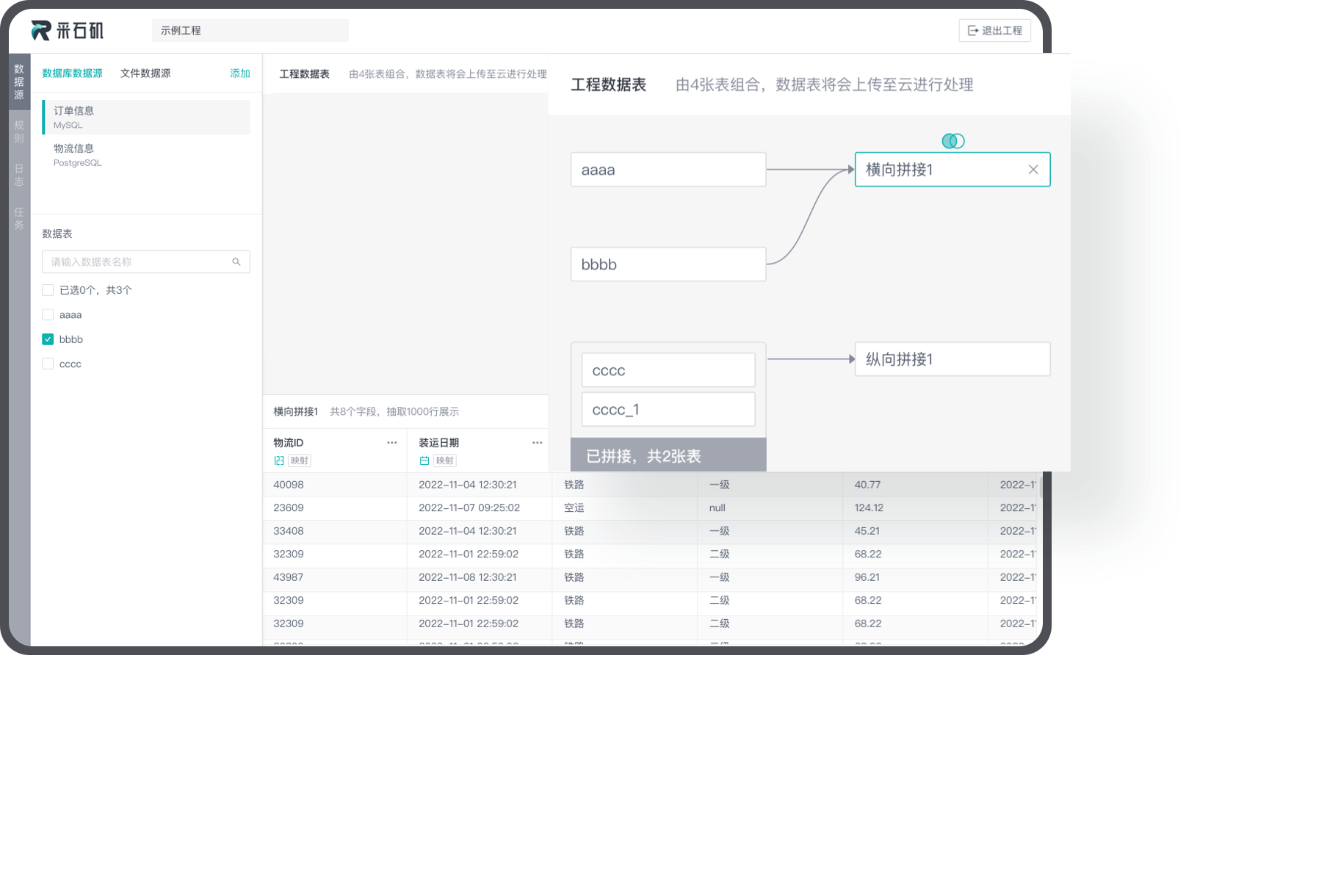
拖拽式数据处理
可通过拖拽的方式快速制作出高度可视化和交互性的报表,让用户更加直观地了解数据的分布和关系。
支持多种数据来源
提供传统数据库、非结构化数据、半结构化数据的接入和数据导入的能力,提供丰富的数据源的访问功能,实现数据的多源接入。
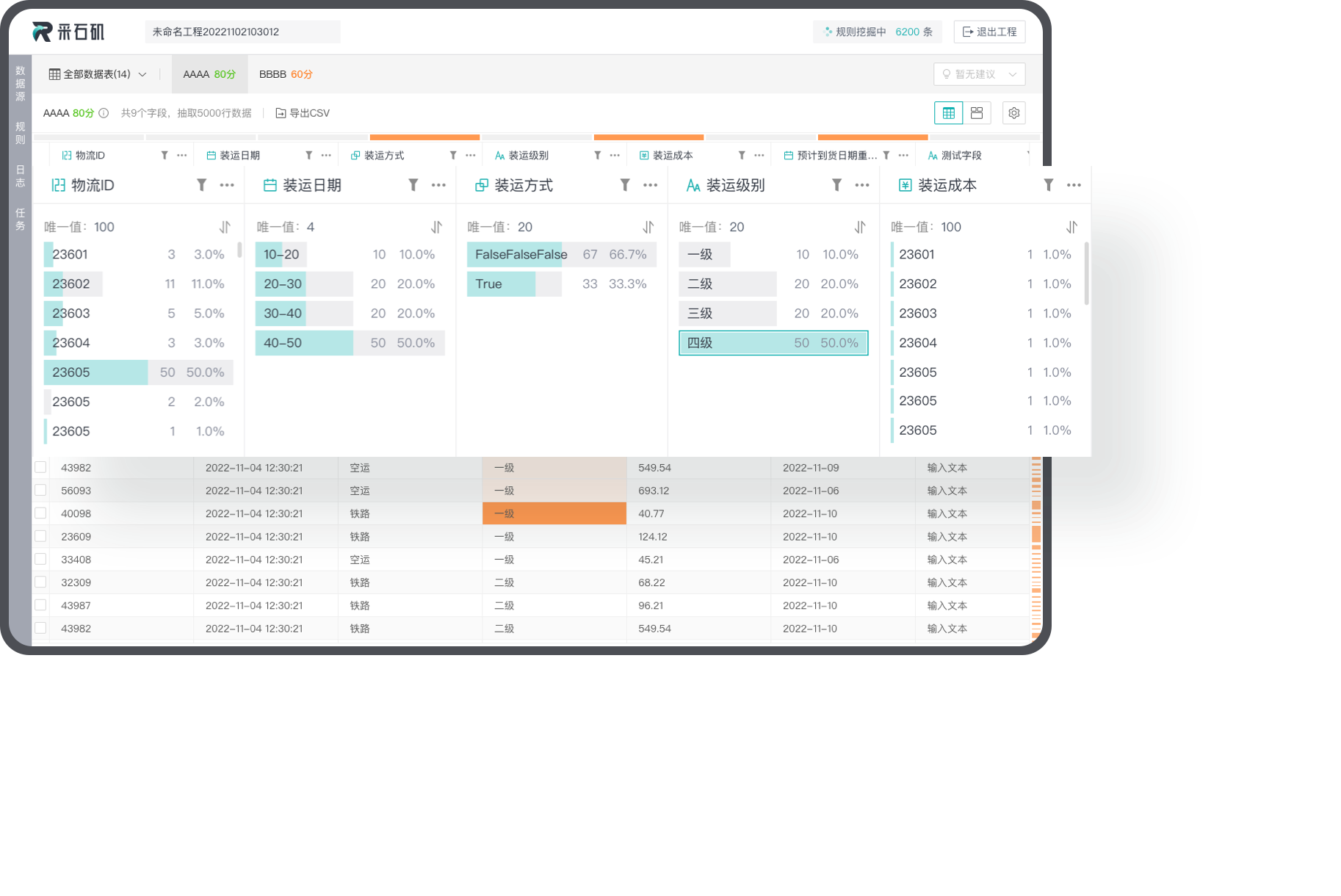
数据剖析
采石矶提供了全方位、可视化的数据剖析功能,可以从不同层面、不同维度全面了解用户数据。
全方位数据剖析
将已有的数据质量问题识别规则和数据标准结合起来,对用户数据进行全面的体检,获得空值字段、数据值类型、值域分布等信息。
剖析结果可视化
提供可视化的剖析报告,使用户对数据有一个完整的评估。用户可以点击查看数据冲突详情,高效探索数据表中的数据情况。
规则发现
提供数据自身规律的发现,使用户快速了解自己的数据内容和相关的规律,提供给业务用户评细的数据评估报告。
数据规则自动发现
无需代码,实现数据潜在规则的自动挖掘分析,并通过可视化技术,实现数据规则的查看与理解。
逻辑与机器学习结合
结合了逻辑规则的可解释性和AI的深度分析能力,发现数据深层关联,在推理引擎表达规则种类方面超过业界一个数量级。
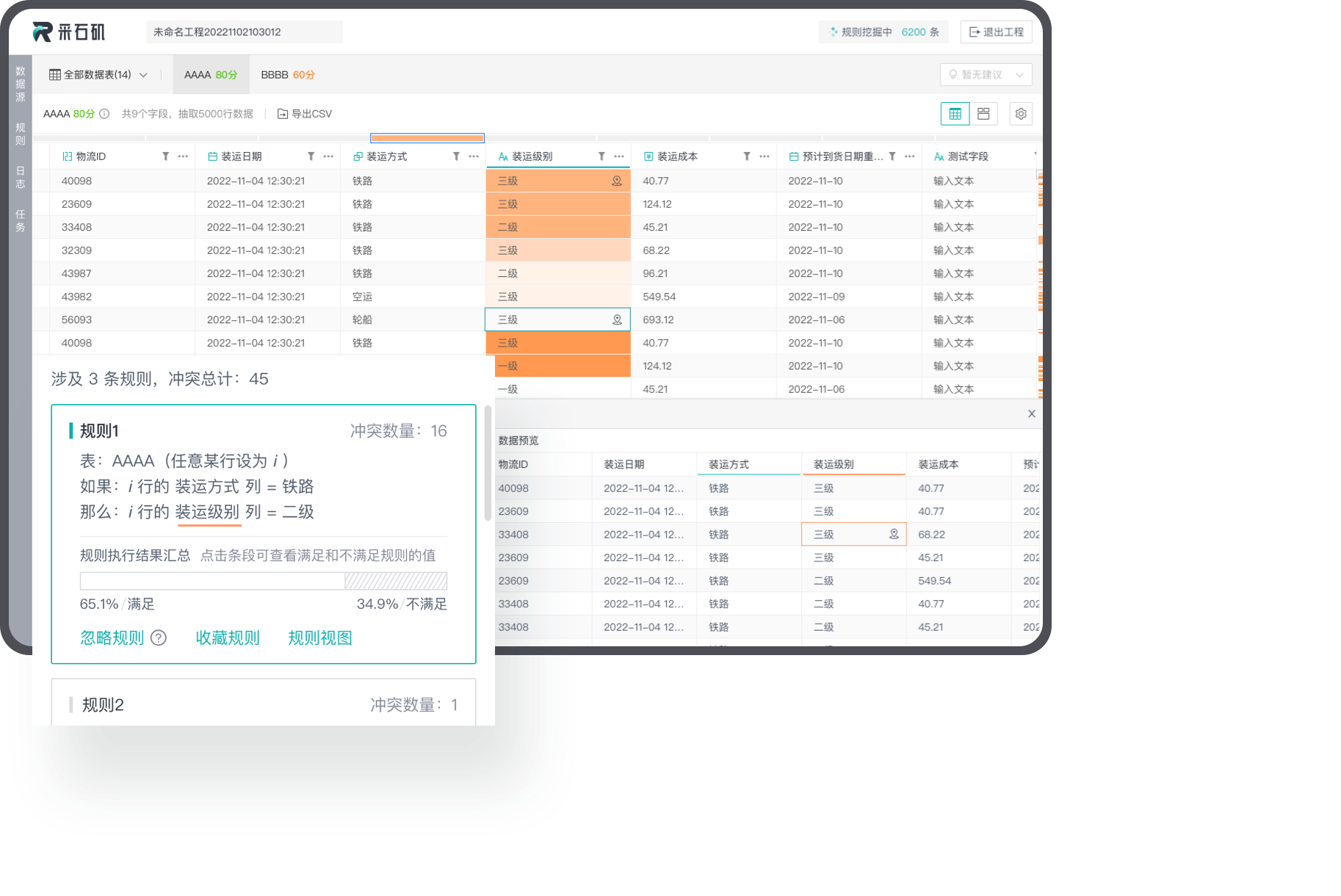
数据查错和纠错
采石矶提供高效的数据检测和修复并行算法,高效完成数据质量检测和错误修复。
数据冲突等级可视化
根据数据冲突严重等级,生成可视化热力图,帮助用户快速定位需关注的数据。
多维度探查问题
通过迭代执行用户指定的规则,找出原始数据中的冲突和错误,可以解决数据的一致性、完整性和准确性问题。
数据自动修正
提供数据检测和修复并行算法,完成数据质量检测和错误修复,并且实时生成操作日志,支持撤销,容错率高。
ER、CR、 MI 、TD相结合的数据修复
通过ER、CR、MI 和 TD的相互作用对数据进行自动修复,提高整体数据质量。
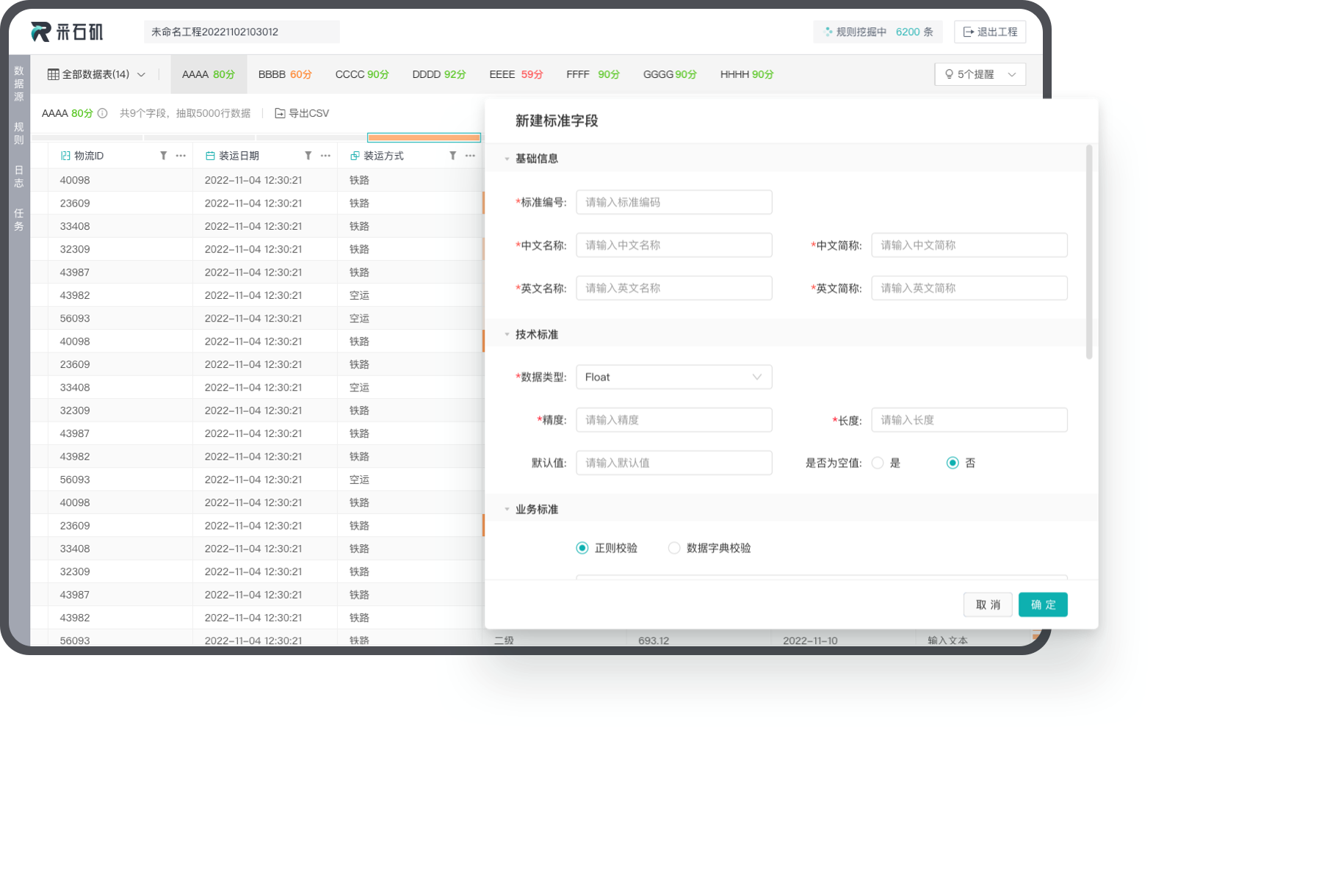
域适应的数据标准化
通过预置丰富的外部知识推断数据角色,根据不同的数据角色实现高效自动的字段标准化。
内置丰富的领域知识
在金融领域的客户身份信息,可以对“姓名、性别、国籍、职业、地址”进行标准化,电商领域的商品描述,可以对“品牌、类目、颜色、标题”进行标准化,等等。
无需人工标注的自动标准化
系统针对数据角色内置了行业标准的规范定义,可以自动将不标准的标准通过语义解析实现标准描述的转化。
深度语义实体解析
提供一整套端对端的实体解析方案,高效且准确地识别异构关系表数据的冗余元组和处理多源数据下的数据整合。
多源实体解析
提供一种将多数据源中的数据进行高效整合的方法,找到最优的记录。
海量数据高效召回
提供一种高效并行的实体召回方法,在海量多源数据中快速且准确地找到冗余实体。
跨领域实体匹配
通过用户少量或者零样本标注,准确地识别出多源数据下的冗余实体,并结合迁移学习技术实现跨越不同领域的实体匹配。
借助大语言模型提升能力
利用提示工程和知识蒸馏等技术,将大语言模型加入在实体解析功能中,进一步提升实体解析的性能。
拖拽式数据处理
可通过拖拽的方式快速制作出高度可视化和交互性的报表,让用户更加直观地了解数据的分布和关系。
支持多种数据来源
提供传统数据库、非结构化数据、半结构化数据的接入和数据导入的能力,提供丰富的数据源的访问功能,实现数据的多源接入。
全方位数据剖析
将已有的数据质量问题识别规则和数据标准结合起来,对用户数据进行全面的体检,获得空值字段、数据值类型、值域分布等信息。
剖析结果可视化
提供可视化的剖析报告,使用户对数据有一个完整的评估。用户可以点击查看数据冲突详情,高效探索数据表中的数据情况。
数据规则自动发现
无需代码,实现数据潜在规则的自动挖掘分析,并通过可视化技术,实现数据规则的查看与理解。
逻辑与机器学习结合
结合了逻辑规则的可解释性和AI的深度分析能力,发现数据深层关联,在推理引擎表达规则种类方面超过业界一个数量级。
数据冲突等级可视化
根据数据冲突严重等级,生成可视化热力图,帮助用户快速定位需关注的数据。
多维度探查问题
通过迭代执行用户指定的规则,找出原始数据中的冲突和错误,可以解决数据的一致性、完整性和准确性问题。
数据自动修正
提供数据检测和修复并行算法,完成数据质量检测和错误修复,并且实时生成操作日志,支持撤销,容错率高。
ER、CR、 MI 、TD相结合的数据修复
通过ER、CR、MI 和 TD的相互作用对数据进行自动修复,提高整体数据质量。
内置丰富的领域知识
在金融领域的客户身份信息,可以对“姓名、性别、国籍、职业、地址”进行标准化,电商领域的商品描述,可以对“品牌、类目、颜色、标题”进行标准化,等等。
无需人工标注的自动标准化
系统针对数据角色内置了行业标准的规范定义,可以自动将不标准的标准通过语义解析实现标准描述的转化。
多源实体解析
提供一种将多数据源中的数据进行高效整合的方法,找到最优的记录。
海量数据高效召回
提供一种高效并行的实体召回方法,在海量多源数据中快速且准确地找到冗余实体。
跨领域实体匹配
通过用户少量或者零样本标注,准确地识别出多源数据下的冗余实体,并结合迁移学习技术实现跨越不同领域的实体匹配。
借助大语言模型提升能力
利用提示工程和知识蒸馏等技术,将大语言模型加入在实体解析功能中,进一步提升实体解析的性能。
Item 1 of 6