Skip to content 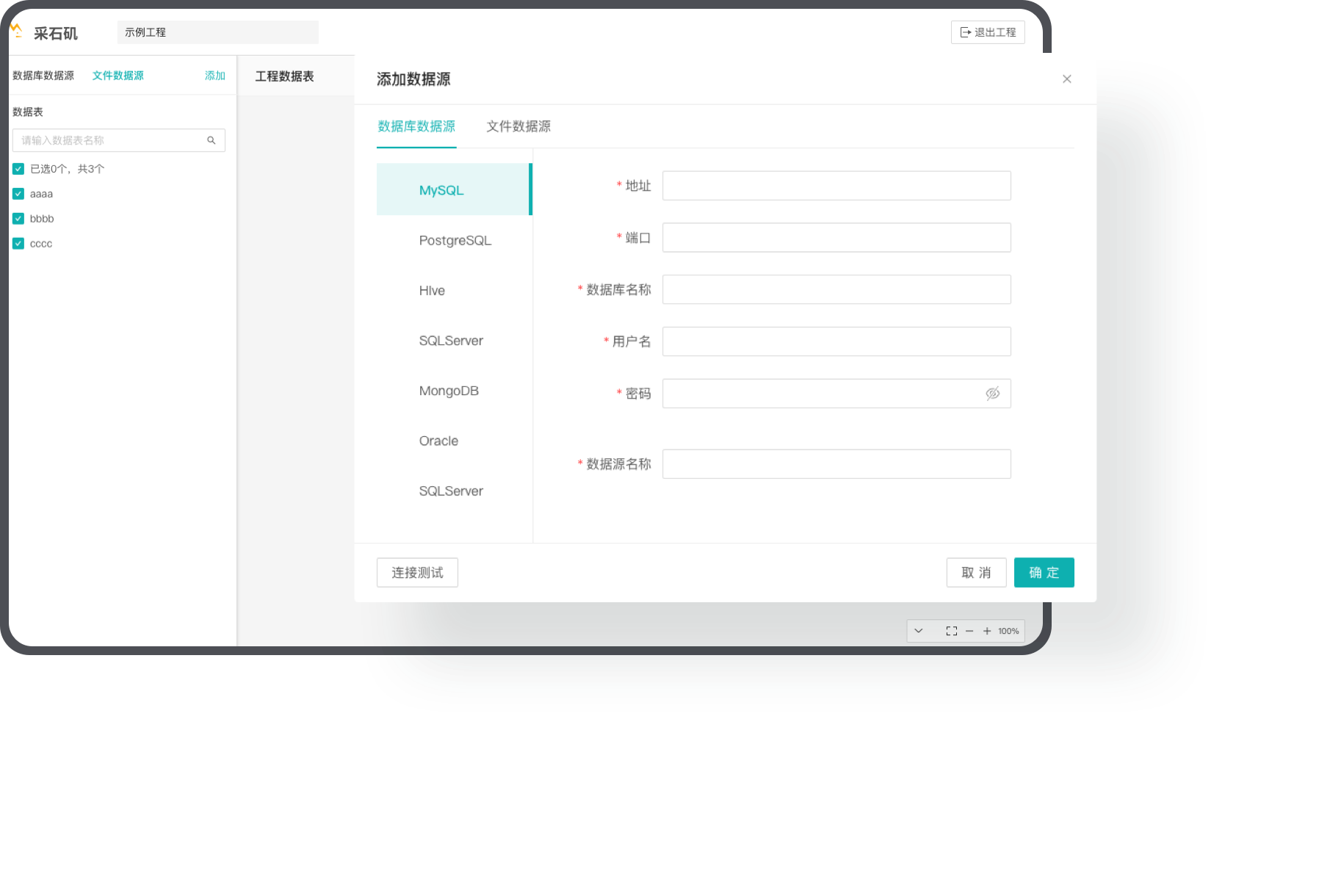

 Grandhoo
GrandhooRock
An intelligent system for evaluating and improving data quality by combining rules and machine learning
Vision
Prepare data easily and efficiently and allow enterprises to access required data at any time
Theory
Entity Enhanced Rules (REEs) for Data Quality Build a self-enhancing system that automatically solves data quality issues by unifying logical rules and machine learning models
Technology
Provide automated intelligent solutions, comprehensive and in-depth diagnosis to fix data problems
Challenges
Challenge 1:
Machine learning or logic deduction?
ML has strong ability of expression, and rule is better for reasoning
No existing systems unify them efficiently and effectively
Challenge 2:
Performance in big data?
How to handle big data efficiently and achieve the parallel scalability
Challenge 3:
Functionality of data quality?
Now only conflict resolution and entity resolution are mainly considered in data quality
Are there any aspects of functionality in data quality?
Rock addresses data quality challenges based on original theory
Unifying logical rules and machine learning
Fully automatic parallel rule discovery
Error correction with correctness guarantee
Parallel error detection and incremental detection
Incremental computation in response to updates
How can it
Easy to get started
Handle data by drag and drop operations without handcraft coding, so that users can get started quickly and easily
User-friendly interfaces
Provide clear and hierarchical visualization to display data relationships and business logic
Interpretability
Embed machine/deep learning models as predicates in logic rules, to facilitate understanding and enable interpretability
All-in-one
Offer a full range of functionalities, including data accessing, rule discovery, error detection and error correction in an end-to-end data quality solution
Starting a New Journey of Data Processing with Rock
Data processing
Rule discovery
Access preparation
Data profiling
Error detection and correction
Visualization
Provide clear visualization for quick and easy data analysis
Automation
Automatic execution of data cleaning tasks without handcraft coding
Intelligence
Intelligent data profiling and error correction with a rigorous scoring mechanism to ensure data processing in a logical and systematic manner
Data Access
For data sources that require quality analysis and processing, we enable unified data access and centralized management, and support various queries via data labels.
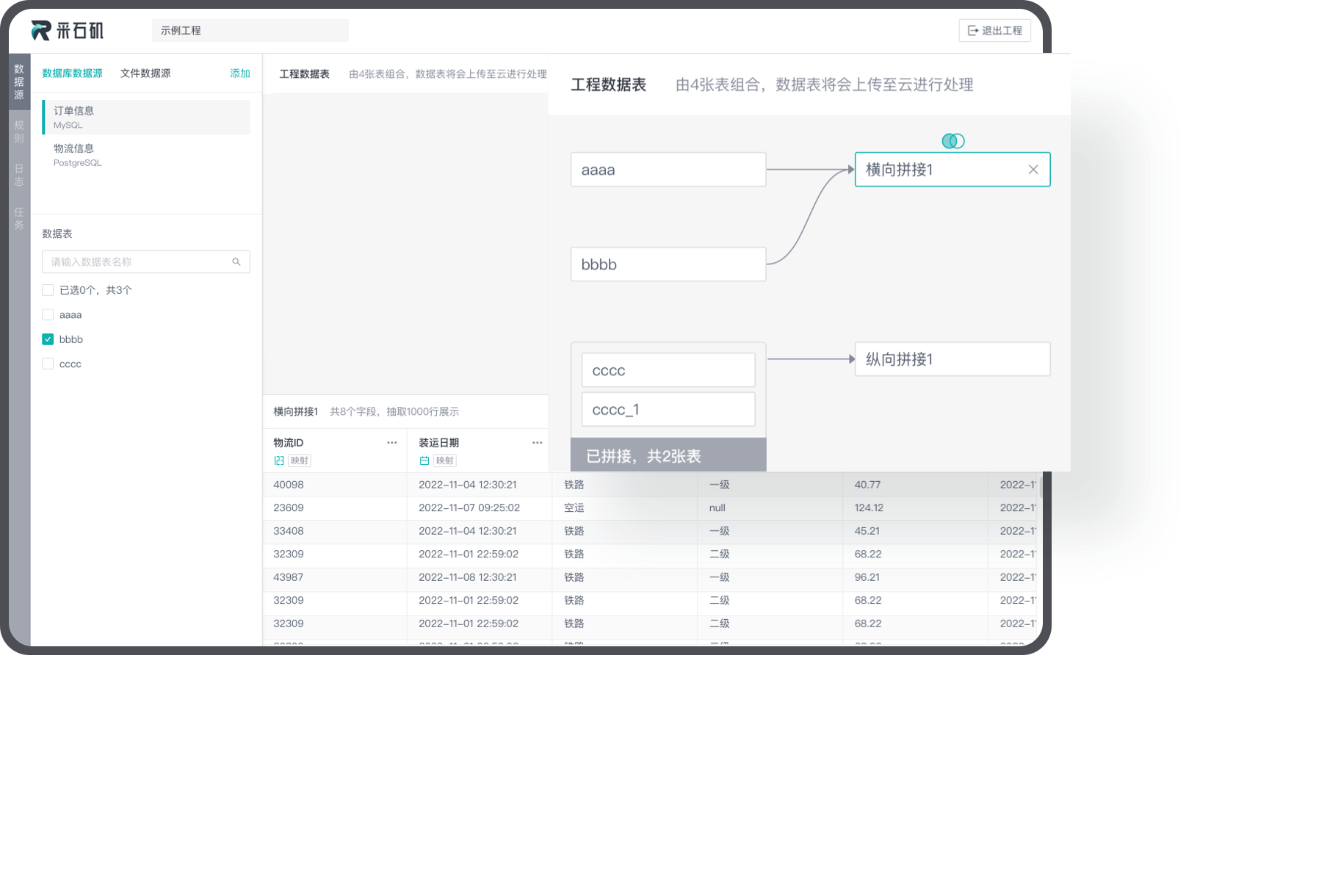
Drag-and-drop data processing
By dragging and dropping, users can efficiently create visible and interactive reports, allowing them to have an intuitive understanding of data distribution and relationships.
Support multi-source data
Support the access and import of data from traditional databases, unstructured data, and semi-structured data, and offer a full range of functionalities to access various data sources and integrate multi-source data.
Data Profiling
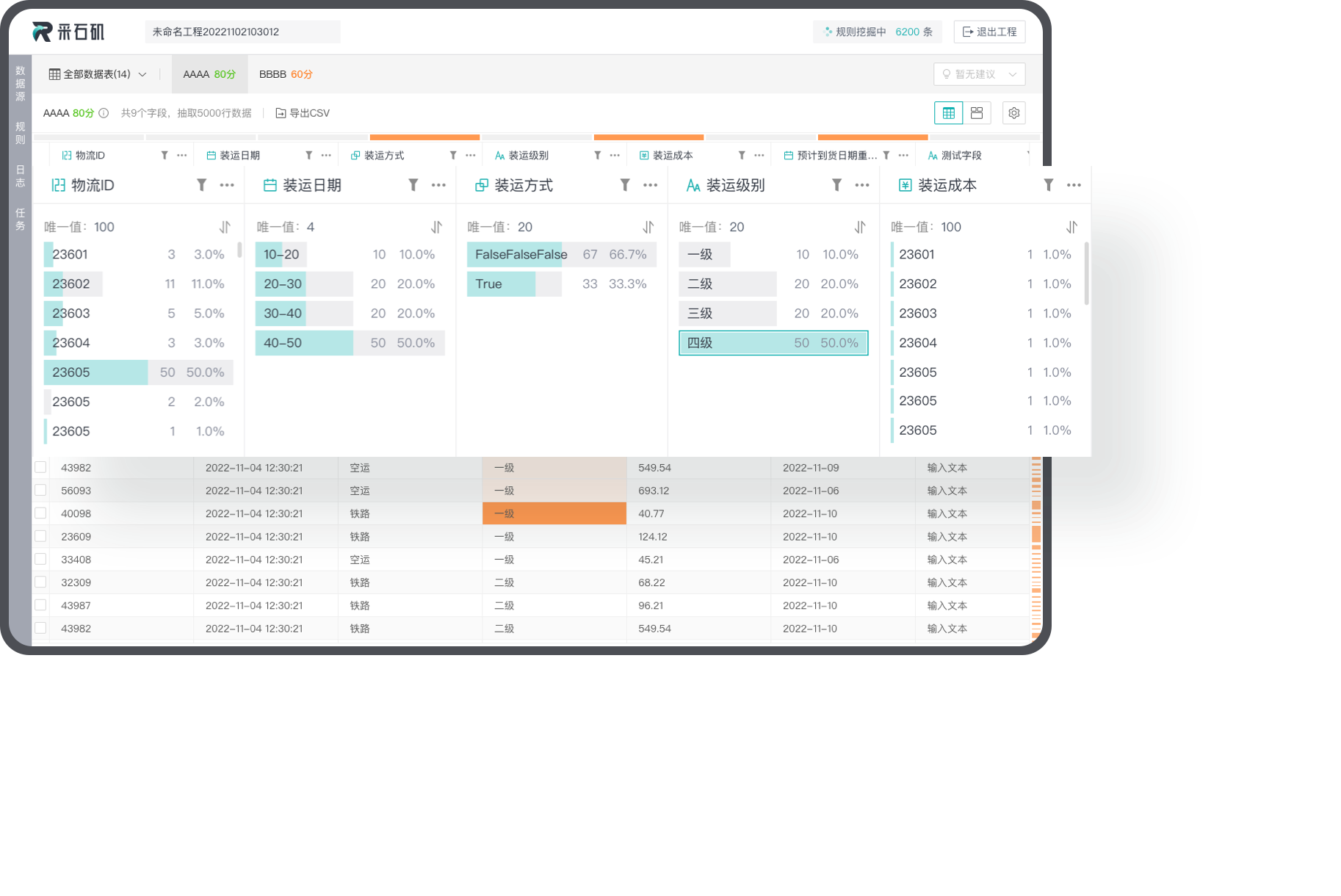
Rock provides comprehensive and visible data profiling capabilities, allowing users to fully understand their data from different perspectives and dimensions.
Comprehensive data profiling
By combining existing data quality rules and data standards, we conduct comprehensive examination of user data, summarizing information such as null values, data types, and value distributions.
Visualization of profiling results
We provide profiling reports with clear visualization, allowing users to have a complete understating of their data. Users can view details of data conflicts and efficiently explore the data status in the data tables.
Rule Discovery
Support automatic rule discovery for users to quickly understand their data and the underlying patterns, and provide detailed evaluation reports for business users.
Automatic rule discovery
Discover potential data quality rules automatically without handcraft coding, and visualize the rules for better understanding.
Combination of logic and machine learning
By combining logic rules with AI, we offer both interpretability and in-depth analysis, and outperform existing inference engines in terms of rule types supported.
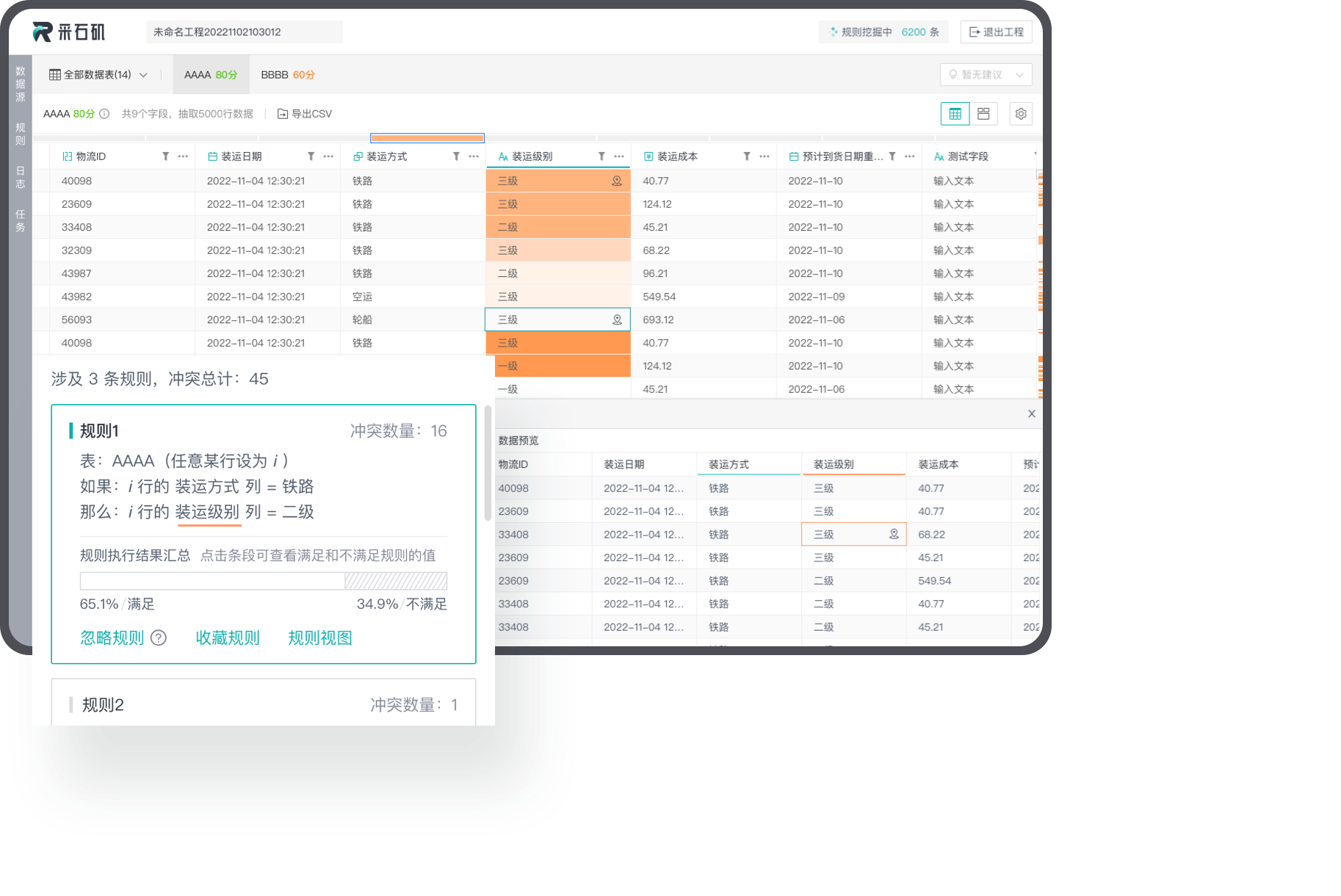
Error detection and error correction
Rock supports efficient parallel algorithms for error detection and error correction.
Visualization of data conflicts
Generate heat maps based on the conflict levels and help users identify critical data.
Exploration from multi-perspectives
By iteratively executing rules, conflicts and errors can be identified, improving data consistency, integrity, and accuracy.
Automatic error correction
Provide parallel algorithms for error detection and error correction, generate real-time operation logs, support undo actions with a high fault tolerance rate.
A unified process of ER, CR, MI, and TD
By leveraging the interaction of ER, CR, MI, and TD, data can be automatically repaired, improving the overall data quality.
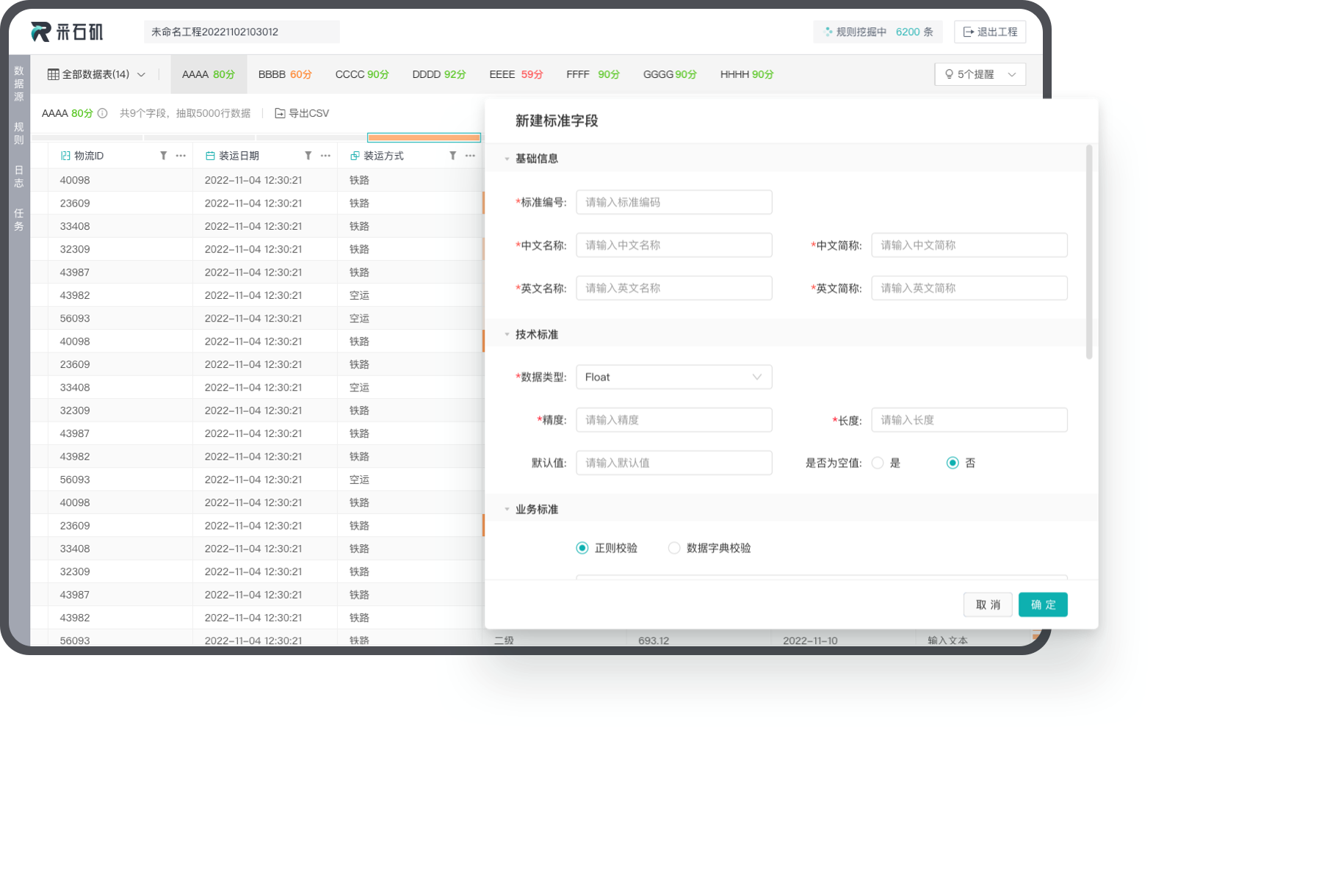
Domain-adaptive data standardization
By leveraging external knowledge, Rock infers the characteristic of data and conduct automatic standardization based on the characteristic inferred.
Incorporation of domain knowledge
In the financial domain, customer identities, such as name, gender, nationality, occupation and address, can be standardized. Moreover, in the e-commerce domain, product descriptions, such as brand, category, color, title, can also be standardized.
Automatic Standardization without Handcraft Annotation
Rock incorporates industry-standard specification and is able to automatically transform non-standard terms into standard ones via semantic parsing.
Deep Entity Resolution
Rock gives an end-to-end solution for ER, by efficiently identifying records of the same entity when data is integrated from different sources.
Multi-source entity resolution
Provide an efficient integration algorithm for data from different sources and identify the best records.
Efficient entity blocking from large-scale data
Provide an efficient parallel entity blocking method to quickly and accurately identify redundant entities in massive multi-source data.
Cross-domain entity matching
Identify redundant records from multi-source data in a zero-shot or few-shot learning manner and incorporate transfer learning techniques to achieve effective entity matching across different domains.
Enhancing capabilities with Large Language Models
Incorporate large language models into entity resolution to further enhance the performance by utilizing techniques such as prompt engineering and knowledge distillation.
Drag-and-drop data processing
By dragging and dropping, users can efficiently create visible and interactive reports, allowing them to have an intuitive understanding of data distribution and relationships.
Support multi-source data
Support the access and import of data from traditional databases, unstructured data, and semi-structured data, and offer a full range of functionalities to access various data sources and integrate multi-source data.
Comprehensive data profiling
By combining existing data quality rules and data standards, we conduct comprehensive examination of user data, summarizing information such as null values, data types, and value distributions.
Visualization of profiling results
We provide profiling reports with clear visualization, allowing users to have a complete understating of their data. Users can view details of data conflicts and efficiently explore the data status in the data tables.
Automatic rule discovery
Discover potential data quality rules automatically without handcraft coding, and visualize the rules for better understanding.
Combination of logic and machine learning
By combining logic rules with AI, we offer both interpretability and in-depth analysis, and outperform existing inference engines in terms of rule types supported.
Visualization of data conflicts
Generate heat maps based on the conflict levels and help users identify critical data.
Exploration from multi-perspectives
By iteratively executing rules, conflicts and errors can be identified, improving data consistency, integrity, and accuracy.
Automatic error correction
Provide parallel algorithms for error detection and error correction, generate real-time operation logs, support undo actions with a high fault tolerance rate.
A unified process of ER, CR, MI, and TD
By leveraging the interaction of ER, CR, MI, and TD, data can be automatically repaired, improving the overall data quality.
Incorporation of domain knowledge
In the financial domain, customer identities, such as name, gender, nationality, occupation and address, can be standardized. Moreover, in the e-commerce domain, product descriptions, such as brand, category, color, title, can also be standardized.
Automatic Standardization without Handcraft Annotation
Rock incorporates industry-standard specification and is able to automatically transform non-standard terms into standard ones via semantic parsing.
Multi-source entity resolution
Provide an efficient integration algorithm for data from different sources and identify the best records.
Efficient entity blocking from large-scale data
Provide an efficient parallel entity blocking method to quickly and accurately identify redundant entities in massive multi-source data.
Cross-domain entity matching
Identify redundant records from multi-source data in a zero-shot or few-shot learning manner and incorporate transfer learning techniques to achieve effective entity matching across different domains.
Enhancing capabilities with Large Language Models
Incorporate large language models into entity resolution to further enhance the performance by utilizing techniques such as prompt engineering and knowledge distillation.
Item 1 of 6