Skip to content 


 Grandhoo
GrandhooQuality Assessment of Data Transaction
Overview
The digital age has ushered in an unprecedented data explosion, where data has gradually become an asset. Data quality has become a crucial aspect in determining the quality of these assets. With the advancement of big data, the increasing richness of data has presented new challenges and difficulties in improving data quality. A data quality strategy is proposed, which involves four main aspects: establishing a data quality assessment system, implementing the collection, analysis, and monitoring of data quality information, establishing a mechanism for continuous improvement, and enhancing metadata management. By optimizing and improving from various angles, a comprehensive quality management and evaluation system is ultimately formed, providing high-quality data support for information systems.
Challenges
Difficult to quantify data quality assessment standards
While evaluation dimensions, including completeness, accuracy, uniqueness, consistency, timeliness, and validity, have well-defined definitions, it remains a challenge to quantify these aspects during data quality assessment.
Difficult to quantify data quality assessment standards
Quality assessment heavily depends on rules and field standards, and currently, the creation of rules and field standards primarily relies on manual input from business personnel.
Slow execution speed and low efficiency
Traditional rule and field standard execution demonstrates lower efficiency, making it incapable of meeting the execution of rules and field standards on a large volume of data.
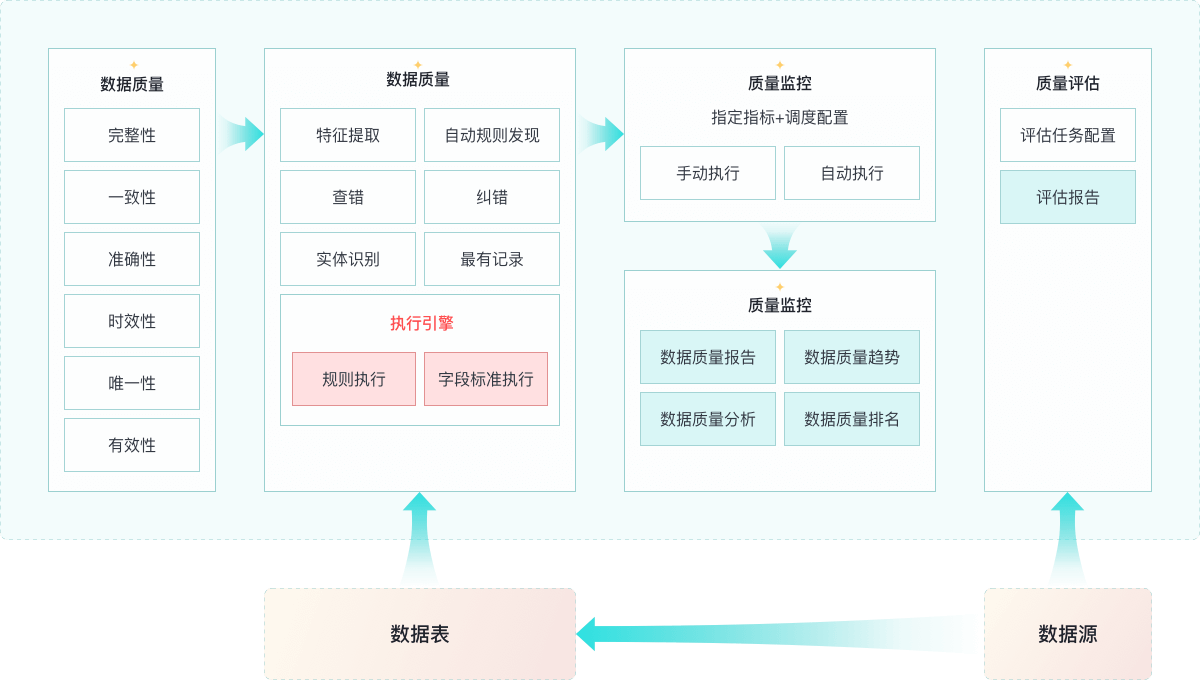
Architecture
Benefits
Bind rules and rule models
Automatically recognize auto-discovered and manually entered rule model types and bind them with customizable weights. Quantitatively assess data quality in the rule model dimension by binding rules to the rule model and configuring weights, resulting in an intuitive score.
Discover rules automatically
Combine original REE theory and industry a priori knowledge to automatically discover rules and field criteria, replacing a large number of manually handwritten rules and improving efficiency.
High accuracy and efficiency
Utilizes a self-developed distributed rule execution engine to greatly improve the execution speed of rules and field standards. According to authoritative testing by the China Academy of Information and Communication Research, the rule execution speed is more than 32 times faster than native SparkSQL.