Skip to content 


 Grandhoo
GrandhooIndustry Data Standardization
Overview
Due to the scattered storage of data in different organizations or institutions, there are situations in all industries where data cannot be effectively integrated and shared. Even within the same organization, there are different departments, teams or business units, and each department may have its own data management methods and systems, resulting in data being scattered and stored in different places, forming data silos. Moreover, different data formats, naming rules, etc. are used between multiple sources of data, resulting in poor data interoperability. In addition to this, data is often duplicated, redundant, inconsistent, etc., and needs to be cleaned and integrated. However, high-quality data analysis applications require accurate, diverse and real-time training data, so there is an urgent need for a solution that can integrate data from multiple sources in the industry, ensure consistency of data meaning and can be continuously updated.
The " Industry Data Standardization Solution " of Rock System supports automatic analysis of data characteristics, matching and identification of fields with the same meaning, management of field standards, formulation of industry common data specifications, entity disambiguation, entity fusion, automatic identification of related data, which helps to improve the quality and management efficiency of data, and promotes sharing and use of data, unleashing the potential value of data. and use, and release the potential value of data.
Challenges
Difficulty in integrating heterogeneous data from multiple sources. The field names, lengths and definitions of the same data in different systems are not exactly the same, which increases the difficulty of field mapping, management and utilization.
It is very difficult to maintain the integrated data, ensure the accuracy of the data and high coverage of industry knowledge, and ensure the freshness of the data.
Due to the different standards of data interfaces, the import of data from different segments requires manual standardization and calibration, resulting in a high cost of continuous data updating.
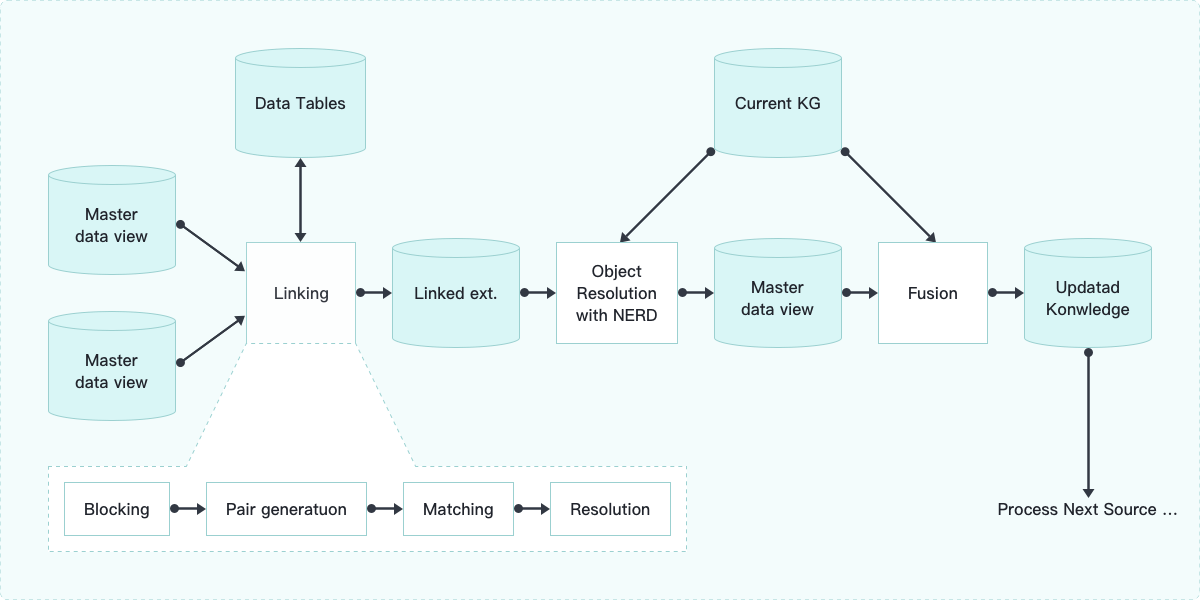
Architecture
Benefits
Data standardization
Formulate adaptive data standards for data roles, and achieve data standardization efficiently and automatically through automatic discovery of data features and pre-set external business knowledge.
Process automation
Combine the strong reasoning ability of REE rules based on original theories and the strong expression ability of NLP models to build a complete set of automatic processes from data collection, data management to data fusion.
Stream-batch Integration
Support the knowledge fusion and construction computing scenarios of hybrid flow and batch through incremental computing.